Last Modified : Wednesday, May 01, 2024
Softmax is a mathematical function used to normalize the values between 0 and 1.
In this article, you will understand:
- What is the Softmax Activation function and its Mathematical Expressions?
- How does it gets implemented using the argmax() function?
- Why Softmax is used in the last layer of the Neural Network only?
- Misconceptions about Softmax
In Deep Learning, Softmax is used as the activation function to normalize the output and scale of each value in a vector between 0 and 1. Softmax is used for classification tasks. At the last layer of the Network, an N-dimensional vector gets generated, one for each class in the Classification task.
Softmax is used to normalize those weighted sum values between 0 and 1, and sum of them is equals to 1, that’s why most people consider these values as Probabilities of classes but it is a misconception, and we will discuss it in this article.
Formula to implement Softmax function:
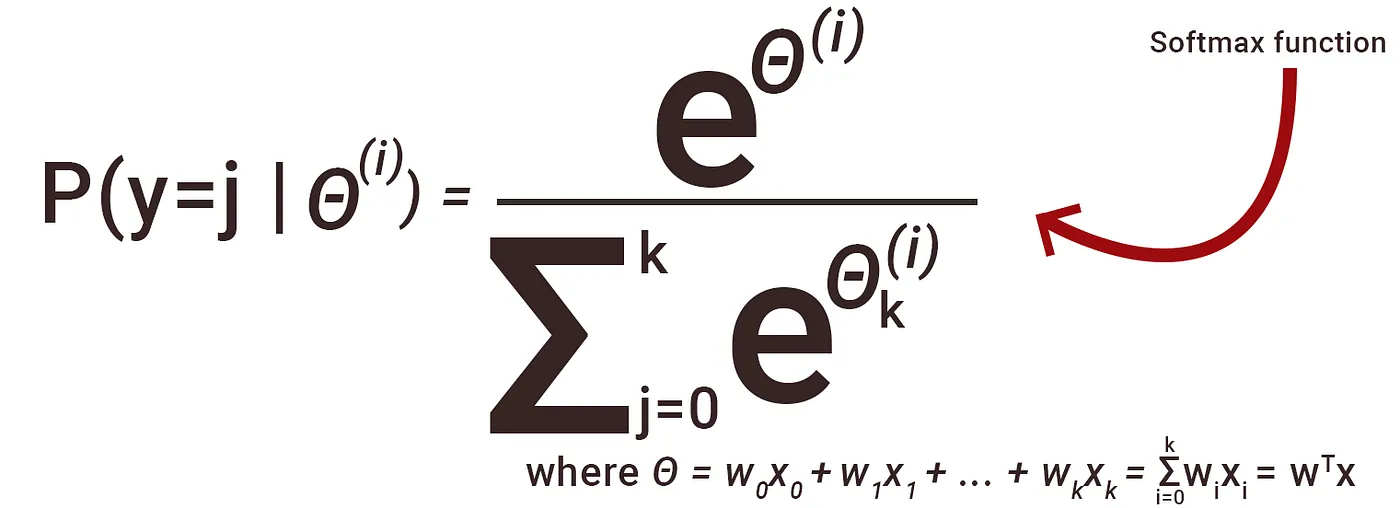
Using this mathematical expression, we calculate normalized values for each class of data. Here θ(i) is the input that we get from the flattened layer.
To calculate the normalized value for each class Numerator is the exponential value of the class and the Denominator is the sum of exponential values of all classes. Using the Softmax function, we get all the values between 0 and 1, and the sum of all values becomes equals to 1. Because of which people consider it as Probability which is their Misconception.
How it uses the argmax() function?
After applying the above mathematical function for every class, Softmax calculates a value for each class that is between 0 and 1.
Now we have several values for each class, to classify which Class the Input belongs to, Softmax uses argmax() which gives it the index of value which have maximum value after applying Softmax.

Why Softmax is used in the Last layer of the Neural Network only?
Now coming onto the important part, Softmax is only used in the last layer to normalize the values, whereas other activation functions (relu, leaky relu, sigmoid, and various others) are used in Inner layers.
If we see other activation function like relu, leaky relu and sigmoid all of them uses the only single value to bring non-linearity. They don’t see what other values are.
But in the Softmax function, in Denominator, it takes the sum of all exponential values to normalize values of all classes. And it takes account of values of all classes to the range, that is the reason we use it in the last layer. To get to know Input belongs to which class by analyzing all the values, then only we can know which class has the highest possibility to be classified.
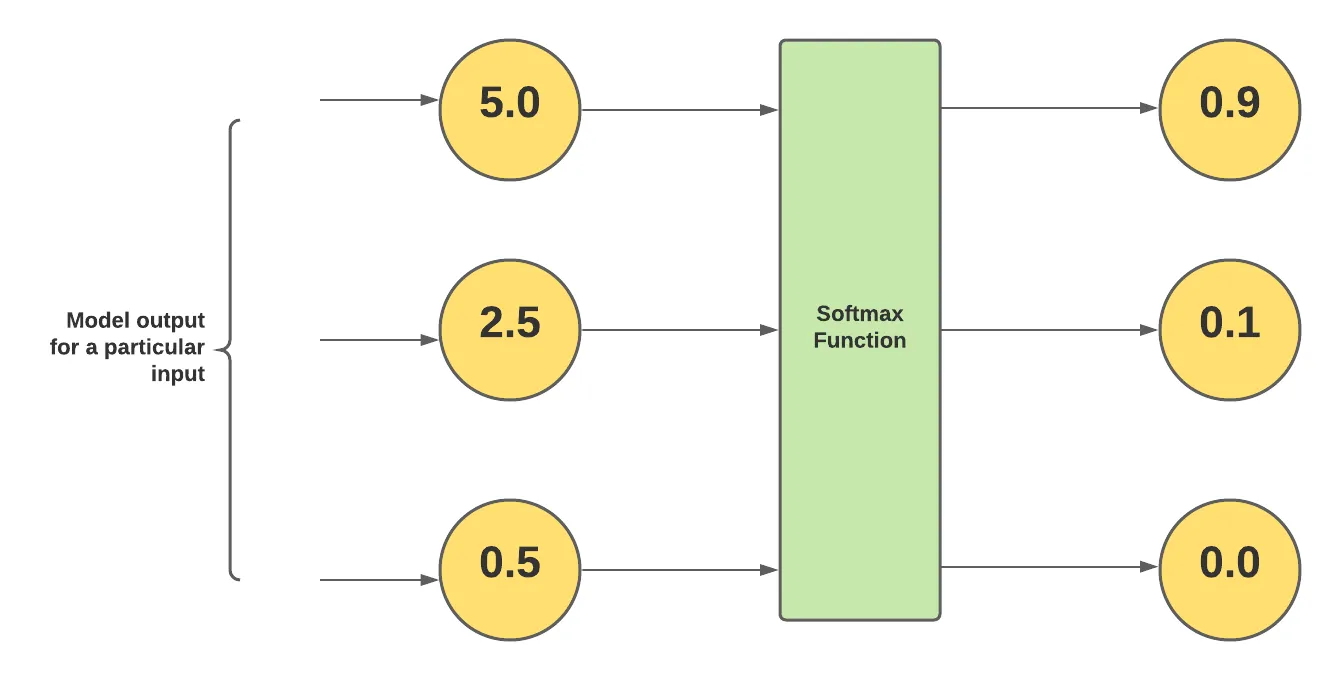
Misconceptions about Softmax
The first and biggest Misconception about Softmax is that It results in the probabilistic value of each class which is totally wrong, It is resulting in a normalized value. This Misconception is because these values give the sum of 1, but they are just normalized values and not Probabilities of classes.
Instead of using Sotmax alone in the last layer, we prefer to use Log Softmax which just does the log of normalized values coming from the Softmax function. Log Softmax is advantageous over Softmax for Numerical Stability, Cheaper Model training cost, and Penalises Larger error(More heavy Penalty for being More Wrong).
This is all about the Softmax function which we use as the Activation function in Neural Network.